2 · the family — and the headline figure
two MoE models, one recipe
| V4-Flash | V4-Pro | (V3.2 ref) | |
|---|---|---|---|
| total params | 284B | 1.6T | 671B |
| activated / token | 13B | 49B | 37B |
| transformer layers | 43 | 61 | — |
| hidden d | 4096 | 7168 | — |
| routed experts | 256 (top-6) | 384 (top-6) | — |
| pre-train tokens | 32T | 33T | — |
| context | 1M | 1M | 128K |
Flash efficient reasoning at smaller budget Pro flagship; "Pro-Max" = max reasoning effort
First two layers use pure sliding-window attention. The first three MoE layers use Hash routing instead of learned routing.
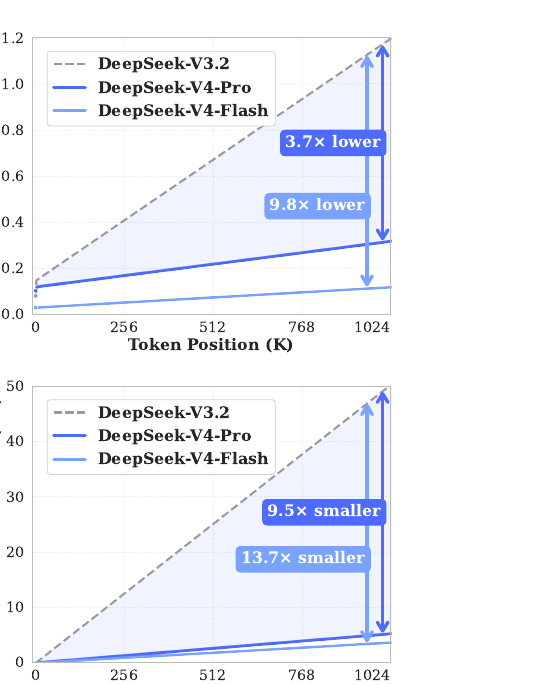
paper Fig 1 (right) — single-token FLOPs and accumulated KV cache
vs sequence length. V4-Pro 3.7×/9.5× lower than V3.2; V4-Flash 9.8×/13.7× lower.
3 · architecture, big picture
V3 lineage with three deliberate upgrades
kept from V3
- DeepSeekMoE: shared + fine-grained routed experts (Dai+ 2024)
- Multi-Token Prediction (MTP) auxiliary loss
- auxiliary-loss-free load balancing + slight seq-wise loss
new in V4
- ① Hybrid attention: CSA + HCA interleaved (replaces V3.2's DSA-on-MLA)
- ② mHC: manifold-constrained hyper-connections (residual upgrade)
- ③ Muon optimizer (with AdamW for embeddings, head, RMSNorm, mHC statics)
small but notable
- routing affinity: Sigmoid → Sqrt(Softplus)
- removed cap on routing target nodes
- first 3 MoE layers use Hash routing
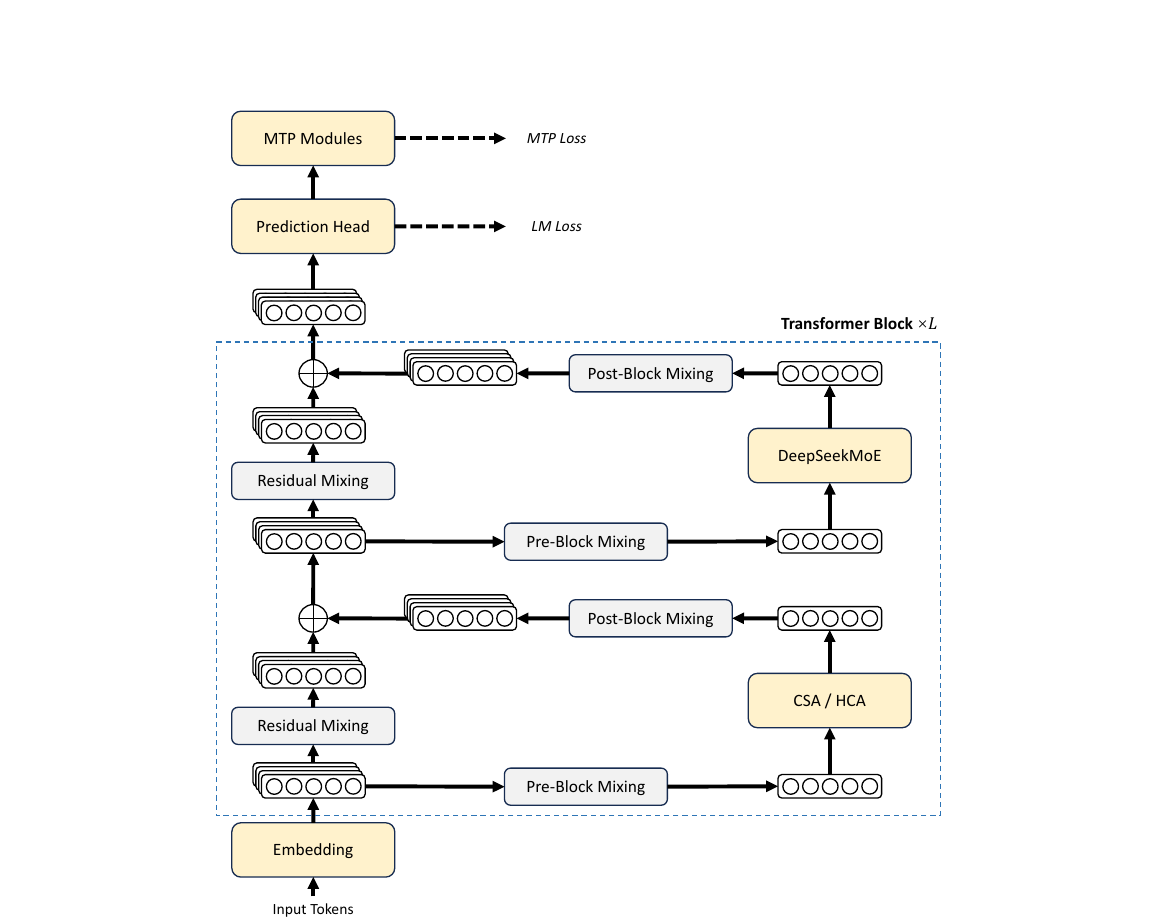
paper Fig 2 — transformer block: pre/post mixing through CSA or HCA
and DeepSeekMoE; mHC residual stream; LM head + MTP modules.
DeepSeekMoE 2401.06066
DeepSeek-V2 (MLA) 2405.04434
DeepSeek-V3 2412.19437
MTP / Gloeckle 2024 2404.19737
5a · CSA in detail
compress, then sparsely select
step 1 — token-level compressor
- two KV streams Cᵃ, Cᵇ + softmax weights Zᵃ, Zᵇ
- each compressed entry pools 2m raw entries (overlapping windows on Cᵇ)
- net: sequence length reduced to n/m
step 2 — lightning indexer
- cheap MQA-style scorer in FP4
- index score It,s via low-rank query ↔ compressed key
- retain top-k (Flash: 512, Pro: 1024)
step 3 — core attention
- shared-KV MQA over selected blocks + sliding window
- grouped output projection keeps the projection matrix tractable
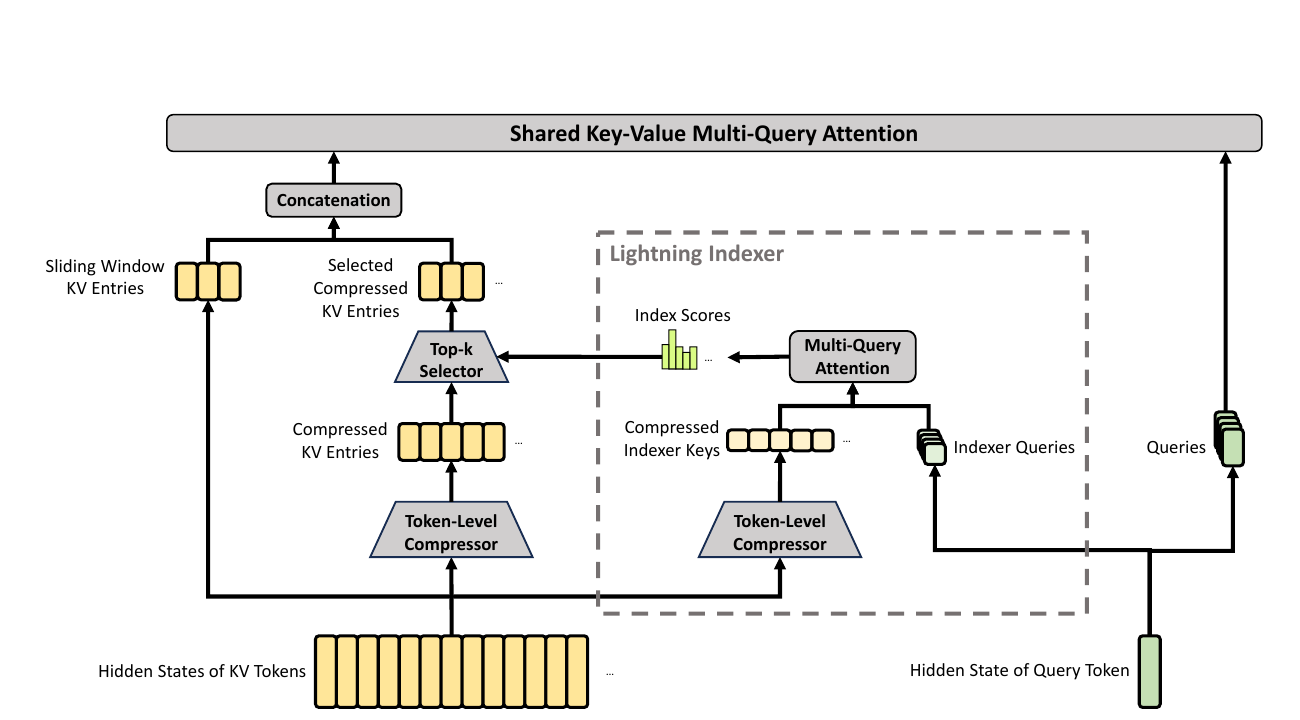
paper Fig 3 — token-level compressor → lightning indexer → top-k selection
→ shared-KV MQA, with a sliding-window branch alongside.
5b · HCA + the small-but-important bits
and where the 2% KV figure comes from
HCA flow
- single compressor, no two-stream overlap
- m' = 128 → 128× cache shrink on the compressed branch
- dense MQA over compressed entries + sliding window
- same shared-KV + grouped output projection as CSA
shared tricks for both
- RMSNorm on Q & KV → no exploding logits, no QK-Clip needed
- partial RoPE on last 64 dims; trick of adding RoPE at
−ion outputs to recover relative position after compression - extra sliding-window branch for local fidelity
- attention sink logit added to denominator — heads can attend to ~0
QK-Clip / Liu+ 2025 2502.16982
RoPE 2104.09864
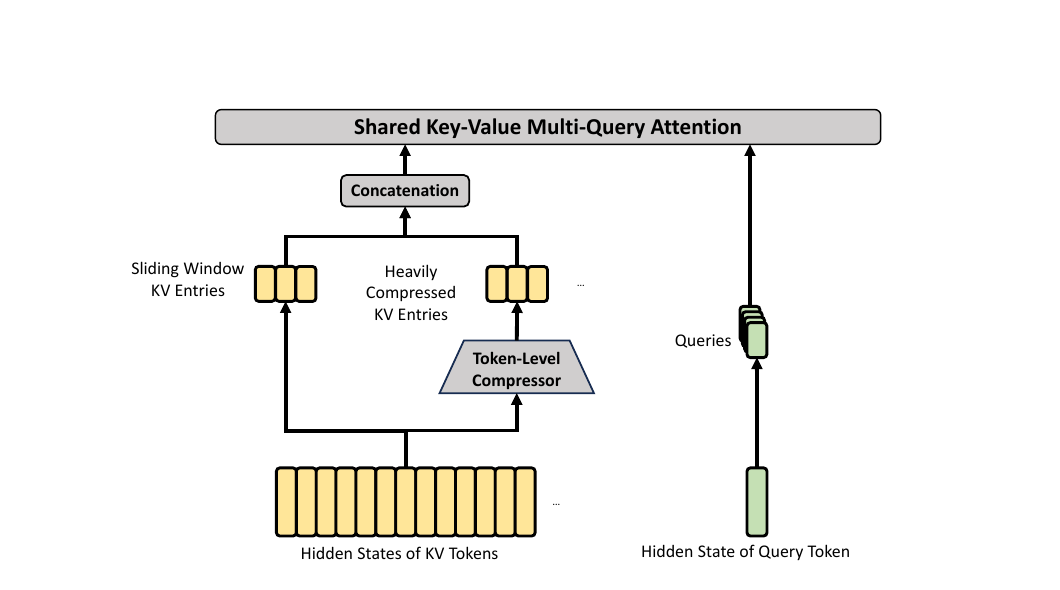
paper Fig 4 — HCA: single heavy compressor, dense MQA, sliding-window branch.
Combined storage tricks (FP8 KV with BF16 RoPE dims; FP4 indexer attention) plus
smaller top-k bring V4 to ~2% of BF16-GQA8 baseline KV at 1M context.
8 · infrastructure
what makes 1.6T × 1M tractable
MoE expert parallelism
- fuse dispatch + linear-1/2 + combine into one pipelined kernel
- split experts into waves; comm of next wave hides under compute of current
- theoretical 1.92× speedup vs naive — vs Comet's 1.42×
- lineage: GShard, Switch, TUTEL, FasterMoE, COMET, DeepEP
kernels & precision
- TileLang — tiled DSL, 1.36–1.70× over Triton/FlashAttn-3
- batch-invariant deterministic kernel libs → bitwise reproducible train↔infer
- FP4 (MXFP4) QAT for MoE expert weights and indexer QK path
training framework
- tensor-level activation checkpointing (extended autograd)
- hybrid ZeRO tailored to Muon
- fused / recompute path for cheap mHC
- two-stage contextual parallelism for compressed attention at 1M
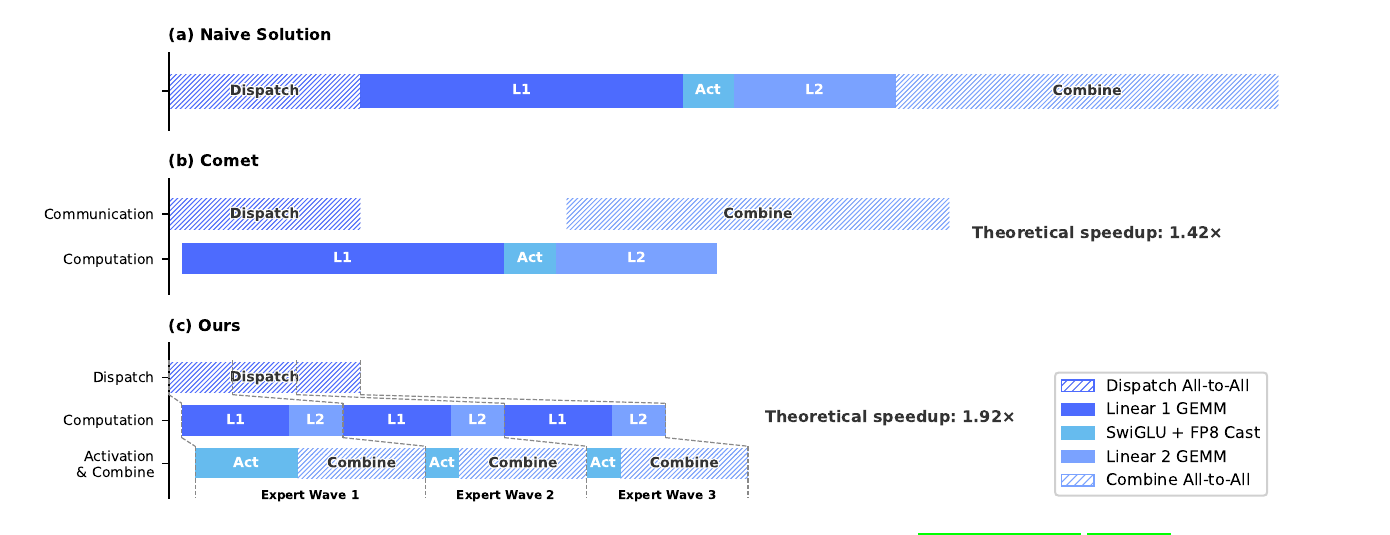
paper Fig 5 — naive vs Comet vs V4's wave-based EP scheme.
Splitting experts into waves so all-to-all of next wave hides under linear-1/2 of current.
why each is exciting
- EP overlap: 1.92× suggests freeing SMs from comm duty entirely (hook-based, not just better tiles)
- FP4 surgically: index scores are smooth ranking signals → FP4's coarse grid is harmless where it would wreck attention logits
- batch-invariant kernels: enables on-policy RL without importance-sampling correction, exact bisection of loss spikes, reproducible evals
- 3FS: open-sourced 7.3 TB/s aggregate-read filesystem underpins teacher-weight streaming and DSec sandboxes
GShard 2020 2006.16668
Switch 2021 2101.03961
TUTEL 2022 2206.03382
COMET 2025 2502.19811
TileLang 2025 2504.17577
FP8-LM 2023 2310.18313
Triton 2021 2107.13042
Defeating Nondet. — Thinking Machines Sept 2025
3FS — github.com/deepseek-ai/3FS
12 · reasoning modes & agent integration
three modes, one model
| mode | use | format |
|---|---|---|
| non-think | routine, low-risk | </think> summary |
| think-high | complex, planning | <think>…</think> summary |
| think-max | frontier reasoning | + injected "be thorough" prompt |
API-surface convergence with OpenAI's reasoning_effort
and Anthropic's budget_tokens for extended thinking.
tool-call schema
- new
<|DSML|>XML format → fewer escape errors than JSON tool calls - interleaved thinking: reasoning preserved across tool turns within an agentic task; flushed on new user message in chat
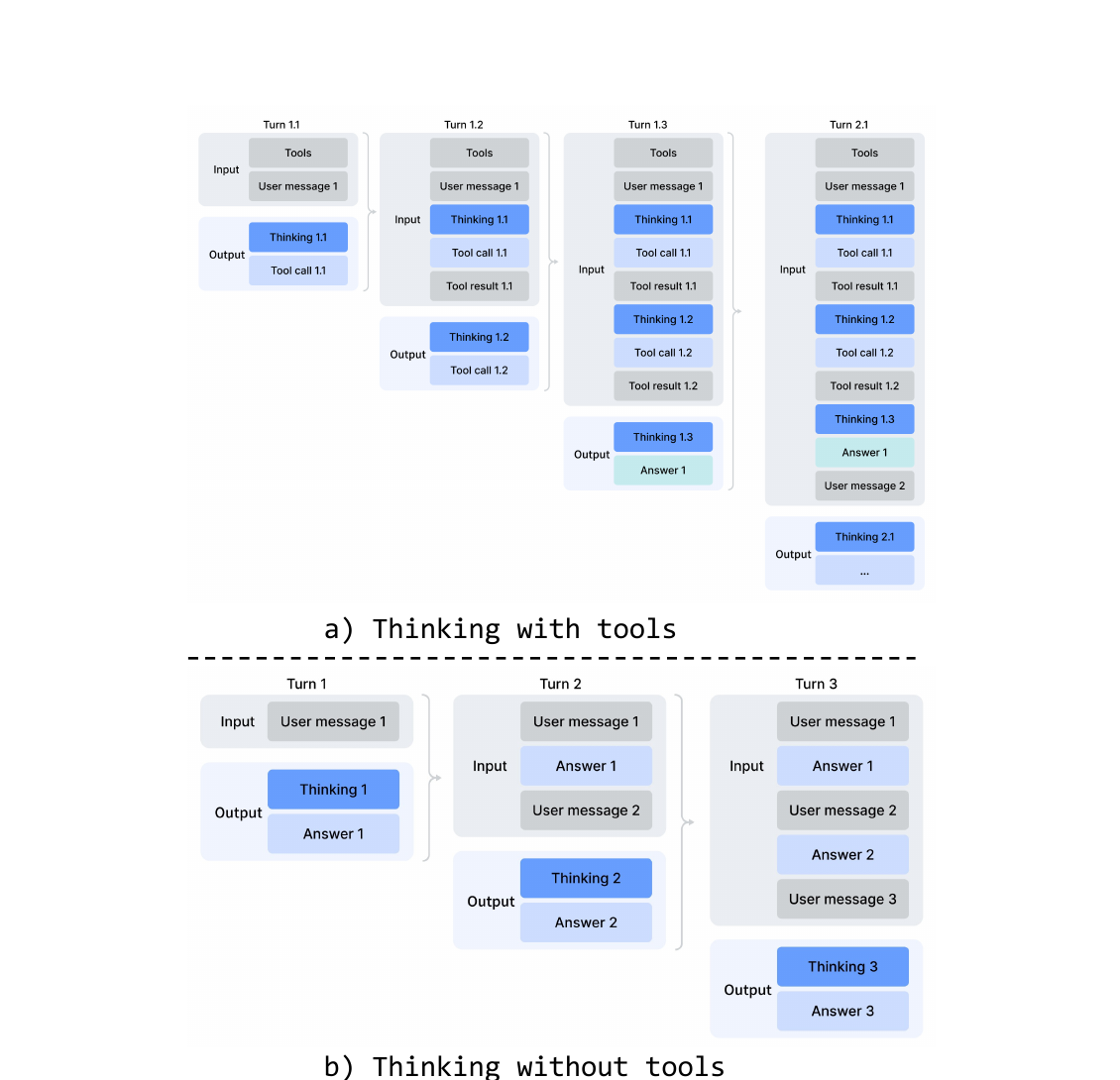
paper Fig 7 — left: tool-calling preserves all prior thinking;
right: chat-only flushes thinking on new user message.
quick instruction
Special tokens that reuse the existing KV cache for auxiliary tasks — no separate small model, no re-prefill:
<|action|> need search? ·
<|query|> gen query ·
<|authority|> need authoritative source? ·
<|domain|> classify ·
<|extracted_url|> / <|read_url|> ·
<|title|> conv title
14 · long-context behavior
1M tokens isn't just declared, it works
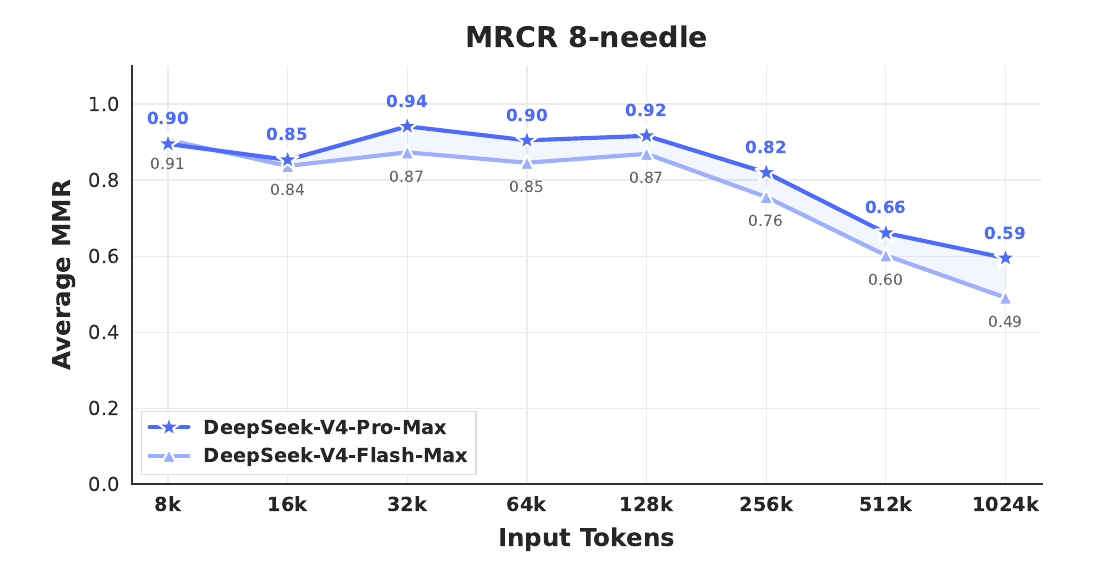
paper Fig 9 — MRCR 8-needle; stable through 128K, gradual decay past 256K.
where it actually pays off
- Codeforces 3206 (≈ rank 23 worldwide) — first open model on parity with frontier closed
- Putnam-2025 with hybrid formal+informal: 120/120 perfect under their pipeline
- think-max gives a real, monotonic lift on hard reasoning
- token efficiency on HLE better than V3.2 — same accuracy, fewer thinking tokens

paper Fig 8 — formal reasoning. Left: Putnam-200 practical
regime; right: Putnam-2025 frontier regime, V4 reaches 120/120.
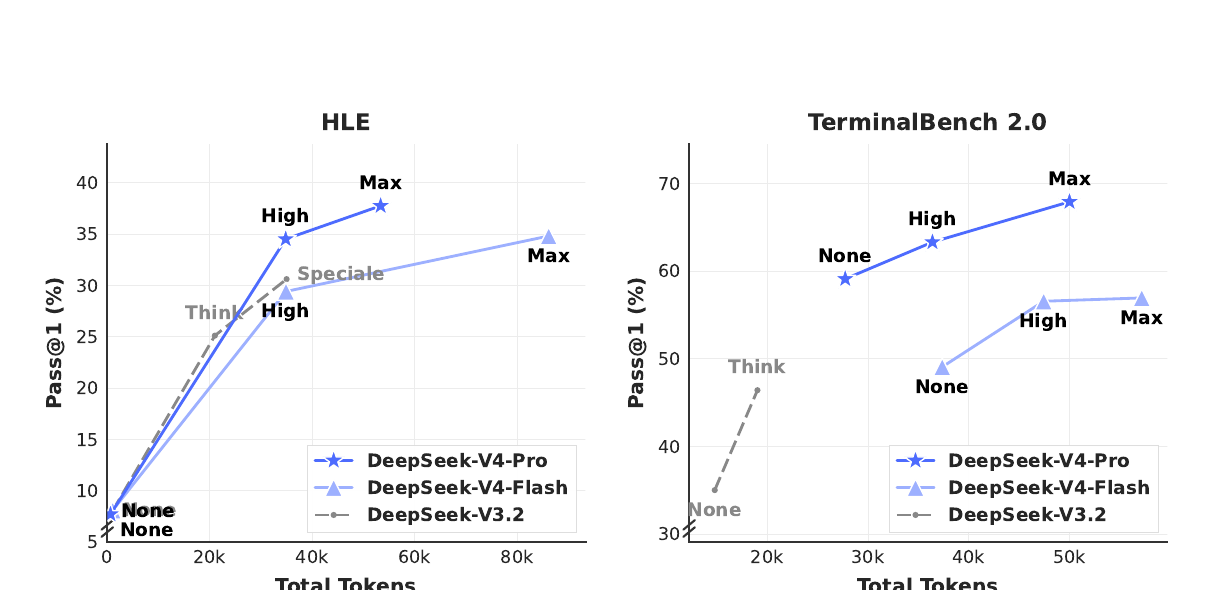
paper Fig 10 — accuracy vs cost on HLE / Terminal-Bench;
V4-Pro-Max sits on the Pareto frontier among open models.